How to Pay for Digital Libraries
Introduction
Jim Gray, the Turing Award winner, once said to me, "may all your problems be technical." We know how to build digital libraries, but we don't know how to make them economically sustainable.
Today there are a vast number of users of digital libraries. The Library of Congress website gets 2 million requests a day for files. In the year 2000 the Library sent out 700 million items (adding up to 9 terabytes) whereas the reading rooms only delivered 1.6 million items to the readers (perhaps one terabyte total, if each were a typical book).[1] Other online digital files also have vast numbers of users; every U. S. faculty member is familiar with the problem of persuading students to use the traditional library as well as the Web for writing papers. But most of these searchers and readers are not paying anything. Since computers, network connections, staff, and the creation of content cost money, how are digital libraries to continue to exist?
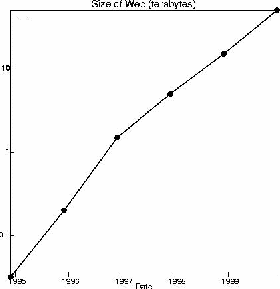
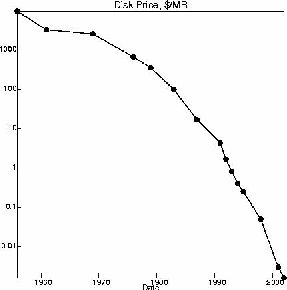
The Web, of course, continues to grow, and the cost of computing equipment continues to decline. The first chart below shows the increase in the Web; the second shows the cost of disk space.[2] Both are on a log-scale; the rate of change continues to be dramatic. We can now easily store a digital library; for the first time in my life, people say that they have empty space on their disk drives.
Figure
1.
Figure 2.
Traditionally, communities (universities or governments) paid for basic library services for their members, with some special services (e.g. photocopying) being fee-based. The Web is world-wide, however. Every university librarian is being asked "why should our university pay to maintain such-and-such a Web service, when most of the users are not our students, faculty, or alumni?"
The situation is aggravated by the desire of some publishers to bypass libraries. Every business now admires the ability of the airlines to charge different prices for the same commodity, and thus get more money from those more able to pay. Publishers would like, ideally, to identify each reader of their publications and extract the maximum payment from each one; why, instead, let them pool their resources, buy only one copy for a library, and hide their marketing demographics?
Organizationally, we do not know who will provide information to scholars in the future. Technological transitions often mean a change in the organization that provides them: Western Union does not run e-mail, the railroads do not fly airplanes, and Winsor & Newton does not make photographic film. Will "digital libraries" will be run by traditional library organizations or by publishers, or by somebody else? There is no shortage of people that want to be in this niche: publishers, bookstores, wholesalers, telecommunications companies, computer centers, and new startups (although enthusiasm is down from the days of 1999-2000). Nor do we know whether there will continue to be as many libraries as there are now. In a world where every town's restaurants, drugstores, and clothing stores are are merely instances of national chains, the independently run public and college libraries seem almost an anachronism.
The organizational solution depends on the economic one. How will digital information delivery be funded?
Among the possibilities are:
Communities pay the full cost (what we do today).
Readers pay by the month or year (subscription fees).
Readers pay by the item received (by transaction).
Authors pay (page charges).
Advertising pays.
Other (bounties, cost avoidance, publicity values).
Each of these items can be weighed, unfortunately, and found wanting.
A. Community support.
Steve Harnad[3] has argued at great length that digital publication is so cheap that community support for free information ought to be affordable. ARL statistics, very roughly, would suggest that the yearly cost of a research library per book is in the range of $3-8, and that per staff member a library might have 7,000-20,000 books.[4] If we assume that a book is about 0.5 MB on average, that means that a typical cost is at least $5 per MB, and that each staff member keeps track of not more than 10 GB. By contrast the San Diego Supercomputer Center manages disk, even replicated for safety, at something like $3000 per terabyte or one-third of a cent per megabyte. The Internet Archive also has prices in the cents per megabyte range and with thousands of gigabytes per staff member.
A fairer comparison to these data facilities might be an offsite deposit library, such as the Northern Regional Library facility of the University of California, which keeps track of some 2 million books with about 20 staff, or some 50 GB per person. Similarly, the Center for Research Libraries has about 4 million books and an annual budget around $4M, or about $1 per book and $2/MB. Even these numbers, although about a factor of 5 better than a library providing the usual academic services, are a factor of 100 larger than computer storage. So digital storage sounds really cheap, as it should with the raw capital cost of disk space running at $179 for 120GB in the summer of 2002, or 0.15 cents per megabyte.[5] That's a tenth of a cent a book-equivalent, whereas building a book storage building, even as a warehouse, runs about $2/book. But it's not that simple.
The numbers above suggest that a repository library is 1/5 the cost of a normal university library. This means that most of the cost of a library is in services -- cataloging, reference, circulation and the like -- and not in the cost of keeping the building heated and painted and answering the occasional request to fetch a book. Nobody who works in a library will be surprised by that. Unfortunately, the implication is that you can't save all that much money by reducing the cost of storage via digitization. If 80% of a library's cost is in services, not storage, even reducing the storage cost to zero leaves the library needing 80% of its budget.
Well, maybe digital libraries won't provide any services. Google can be used instead of a catalog, acquisitions can be done with robot web crawlers, and people looking for reference help can be told to get lost. For expert researchers, that might be of use in some situations. It's not a strategy likely to be thought appropriate or adequate for a university which has a responsibility to teach students. We'll have to hope that it is not widely adopted in response to financial pressures.
There are some savings possible in services. Libraries can share digital files more easily than paper copies, so some of the acquisitions tasks might be shared. And some of the digital material replaces paper material and comes with its own cataloging and the like; for example JSTOR has been deliberately designed to substitute for back-issue files of traditional serials. JSTOR estimates that libraries could save $140M/year by substituting its service for traditional paper storage.[6] So far relatively few libraries have discarded journal issues because JSTOR holds them, but many do move the journals to cheaper storage.
Unfortunately the attempts to share also destroy locality. If the resources provided are not used solely by the community paying for them, why should the community pay? In the past, the number of visitors from one library to another has been relatively small, and whether or not they were charged fees, the impact on the library budget was small. Today the majority of the users of a university site may be outsiders, and they are likely to come from all over the world. For example, the British resource site BUBL (digital library resources for the UK) got only 15% of its identifiable accesses in July 2002 from UK sites.
So why should any university provide a good rather than minimal digital library service? This is the "tragedy of the commons" once again, on a global scale. The danger is that each university will try to cut its library budget, hoping the students will find what they need elsewhere. Fortunately, the library community is very strong in both its public service ethic and its inertia, which should keep things going until the economists can figure a way out.
B. Subscription sales
Another possibility is that digital library services can be provided on a cost-recovery basis. Certainly many publishers are trying this. So far, success is limited. The poster child for Internet subscriptions is the online Wall Street Journal. The chart below shows the number of subscriptions for it and for the runner-up, Consumer Reports.[7]
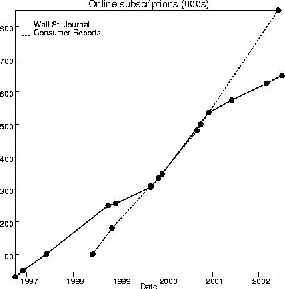
Figure
3.
The Wall Street Journal has more paper subscribers (over 2 million), and Consumer Reports as well (over 4 million). The paper prices are higher ($175/yr for the Wall Street Journal, and $26/yr for Consumer Reports), so the discrepancy in revenue is even larger than the discrepancy in subscription counts, but this is still a substantial on-line subscriber base. If everyone paid full price (there are discounts available in both paper and online modes), the Wall St. Journal would get about 15% as much from online as from paper, and Consumer Reports almost 20%.
A key choice publishers must make is whether to price for individuals or libraries. Clearly, both the Wall Street Journal Interactive Edition ($79/year, less if you subscribe on paper as well), and Consumer Reports ($24/year) are priced to permit individuals to subscribe. But other publications such as JSTOR or Elsevier's "Science Direct" are priced only for libraries. Reed Elsevier reports that in 2001 ScienceDirect sales were up 50%, and their revenue in 2002 from online sales will top $1.5B, so the library subscription model is working here, thanks to elaborate definitions of who is allowed to access material.[8]
An example that may be more relevant from the standpoint of scholarly publishing is the ACM Digital Library, which offers access to all the ACM journals and proceedings online for approximately $100/yr. This is again an individual price, affordable by many individual members of the ACM (a U. S. professional society for computer scientists). The ACM digital library reached 47,000 subscribers in 2001, more than 1/3 of the ACM membership (some of these are getting a student discount). ACM paper subscriptions have dropped about 1/3; however they had been dropping anyway. ACM was caught in a cycle of an increasing number of CS researchers wanting places to put their articles, stimulating the creation of new journals, and spreading the readership ever thinner. ACM found itself printing more articles but fewer copies of each one as the membership distributed its purchases over the additional publications. With luck the digital library will be a partial answer to this since there is no problem with "small production runs" -- articles of interest to only a small specialized group (such as the tenure committee at the author's institution) are just fine in digital form.
There was a time when Internet connectivity was free; there were services hoping to give away connect time in exchange for the right to send ads, or as a hook to sell more complex communications packages. These all died in the marketplace, and people now expect to pay for connectivity. Many for-sale online publications have died off also, after the hype of the dot-com boom collapsed. Yet, there are now some hopeful signs.
A survey of the Online Publishers Association reported in the New York Times on August 1, 2002 estimated that consumers spent $675M on digital goods and services, with 12.4M people paying for some form of content. Business and financial sites collected $214.3M. The total content sales in the first quarter of 2002 were $300M, almost as much as in the first half of 2001, which means that the area is growing strongly.
On balance the subscription model for individuals has not been strongly succesful. It appears that libraries, or some equivalent buying club, remain the most obvious method for people in universities and research institutions to get their information.
C) Transaction payments.
Buying all the parts for a car costs more than buying the whole car. Many publishers used to dream of selling individual articles and getting more money than for magazines. However, this hasn't worked out. Many newspapers now sell their back articles through Newsbank, for example, but with prices at $2.50 an article or more, usage is low. There are several possible explanations of why this business model has not succeeded:
1. the price is too high for the demand;
2. there is enough free stuff out there;
3. librarians and readers are risk-averse.
A price of $2.50 for a single article from a newspaper that may have cost 35 cents for the whole issue on publication day certainly seems high. Of course this is a small amount of money if the information is of commercial value, but not that many older news stories have great value. "Yesterday's newspaper is like yesterday's fish," an old saying goes.
There was a substantial effort in the late 1990s to develop "micropayment" systems. These would have been able to charge a few cents for things efficiently; First Virtual was perhaps the best known. None of these seem to have caught on. First Virtual Holdings started in 1994, became MessageMedia in 1998, and was acquired by DoubleClick in 2002. Cybercash also began operations in 1994 and was bought by Verisign in 2001 as part of a bankruptcy auction.[9]
A sort of Gresham's law also operates because of the amount of free information on the web: why pay for a newspaper article if some free site will provide what appears to be the right information? Few newspapers have the kind of wide-spread name recognition that will cause people to seek them out (the New York Times, of course, being the best known); magazines with general public credibility are even rarer.
Book publishing on the web for downloading is also a much hyped but little used methodology. In 2000 Stephen King tried publishing a book online in installments as shareware (payment on the honor system), with a threat to stop providing new chapters unless 75% of the downloaders paid for it. He quit after six chapters, claiming that only 46% had paid for the last installment, with about 40,000 copies sent out. Few other e-publishers sell any comparable numbers. There was a rash of "e-book" publicity and products in 2001, which has died in the marketplace. Whether it will return when better devices with larger screens and lighter weight appear is unknown.[10]
In addition, many parties in this transaction are risk-averse, and don't like the uncertainty of buy-by-the-item. Journal publishers, for example, have traditionally avoided many conventional business problems by collecting in advance for subscriptions. If the check bounces, you just don't send the magazine. You get six month's float on the money, and you don't need elaborate record-keeping to send out bills. By contrast, selling individual stories carries a need to count usage, compute bills, and chase down customers who don't pay. On the buying side libraries often get their budget once a year and don't like setting aside money for bills which can not be accurately estimated. Users are also often leery of expenses that can mount up quickly. All these considerations push the business away from pay-per-item and towards pay-per-month.
It seems unlikely, therefore, that the eventual support of digital libraries will come from selling individual items by the byte. Perhaps the comparison is to photocopy machines: yes, there are a few of them being used in libraries with coin slots, or similarly in shops like Kinko's, but the bulk of the photocopy machines sold are in offices or homes and are not selling a per-page service.
D. Author-pays.
Years ago Brown and Traub argued that page charges, assessed against authors, would greatly help the finances of journals. By collecting the initial cost of each page from the author, and the incremental costs from the reader, the journal would be economically secure as the number of subscribers or pages changed. Since the incremental cost of papers posted online is virtually zero, the idea of assessing all costs against the authors is attractive. In fact, that's what happens today -- most websites are paid for by the author's employer. Should that be institutionalized in some way, with professional journals charging the authors to pay for their websites, and then not caring who reads them?
Page charges, however, were not a success in the scientific journal field. Many authors, given the choice of professional society journals with page charges and commercial journals without page charges, were happy to publish in commercial journals (which in some cases also offered faster publication or a better chance of having the paper accepted). It may well be that any money saved on page charges was paid back double in subscription fees, but that was the library's problem, whereas page charges usually were paid by the department or research grant. Since the authors route the papers to the journals, it seems likely that the same problem would reappear in the digital world.
Frequently, the organizers of meetings on this subject suggest that "authorities" impose rules on where scientists can publish. They may appeal to university presidents, government funding agencies, or whoever for a rule that requires publication in professional society journals or online. The practicing scientists are likely to resent such rules, however, and they are politically difficult to impose; university presidents have enough trouble telling the faculty where to park their cars, let alone where to publish their papers. An economic solution is almost certain to be more effective, appealing to the author's self-interest. For example Steve Lawrence of NEC showed that online articles are cited more often than paper-only articles.[11] Perhaps this may motivate authors to go to self-publishing on the web in the future. Unfortunately scholarly respect is not the same thing as actually being read. Remember the famous quip "deans can't read, they can only count"; the increasing length of scholarly monographs have led some to say "deans can't read, they can only weigh".
Another problem with page charges is the shifting of costs among institutions. Although we tend to talk about the "scholarly community" and suggest that the readers and authors of journals are the same people, it's not a perfect match. In particular, for scientific journals, there are both university and commercial organizations providing papers and subscriptions. The universities provide a larger share of the papers than they do of the subscriptions. Thus, shifting costs from readers to authors would shift costs from commercial organizations to universities, and the universities are probably less able to bear the burden.
A large part of the difficulty is with prestige. Authors of scientific papers normally publish for credit, promotion and renown, not money. It has proven difficult to persuade authors to send their best papers to an online journal; they fear not being suitably rewarded during tenure decisions, for example. It ought to be possible to quell such fears by using the prestige of either major universities or major scientists. So far, unfortunately, the tenure committees and university presses have been even more conservative than the faculty in general and the most desired publications are still on paper, even if the ones most read are on the Web.
Despite this history, late 2002 saw a major new effort in the biomedical area to create an online journal funded by page charges, the Public Library of Science.[12] Several major scientists, including Harold Varmus, are supporting this attempt to create an online journal with the prestige of Science, Nature or Cell. The Gordon and Betty Moore foundation has provided $9M of initial funding, and the first two journals, PLoS Medicine and PLoS Biology, should appear in 2003. Each article is expected to pay $1,500; funding from the Soros Foundation is available to help authors in countries where this charge might be prohibitive. Reading, downloading or printing the journals will be free. Time will tell whether this attempt will succeed.
E. Advertising
Although advertising has rarely been important in the economics of scholarly journals, it certainly determines the financial health of more popular publications and of broadcast television. Is it possible that advertising could support digital libraries? There's certainly enough total money out there. Just to look at some minor categories, cable TV advertising and Yellow Pages advertising in 2000 were each over $12B. Online advertising, although smaller at about a third of that, is still comparable to total university library budgets.
The chart below shows the rise of online ad spending. There is wide disagreement about these numbers; the historical statistics below are from the Internet Advertising Bureau and the future predictions come from firms such as Jupiter and Forrester. The chart shows both what has actually happened and the predictions made in 1995, 1999 and the current year; you can thus decide whether you wish to believe the current predictions.
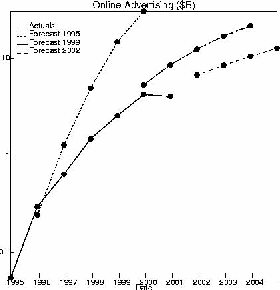
Figure
4.
The market for Internet advertising has been stagnant of late. The most recent quarterly report, showing $1.47B of ads in the third quarter of 2002, was a 1% advance on the previous quarter and an 18% decline from a year earlier.[13] Online advertising has been dropping for six quarters, partly because so much of it was placed by other dot-coms which no longer exist. Advertisers have become discouraged as fewer than 1% of people who view an ad click on it.
Unfortunately, despite the $4 billion total (or more), it's all focussed on a few websites, particularly the very popular ones. The potential for specificity in web advertising is not used as fully as it might be; few sites other than the leading search engines and portals get much advertising. It is hard to imagine enough advertising going to libraries to make a difference. Even in the boom years most small journals, for example, did not attract many ads to their websites, and it is unlikely that libraries, even if they sought out ads more actively, would get many. As the Internet advertising market has matured, the ad placement has gone mostly to a few heavily used sites.
Thinking historically, very few scholarly journals got a large fraction of their budget from advertising, with only a few ads for books and employment positions on their back pages. Libraries have not historically sold advertising, and have not seen much opportunity there. The main "advertising" in a library has traditionally been for donors: buildings, reading rooms, and book purchase funds are named for individuals the way sports arenas are named for corporations. And one problem with computer technology is that its transitory nature and the rate at which it becomes obsolete make donors reluctant to fund it, since whatever their name is on may evaporate in a few years. On balance it seems unlikely that digital libraries will find much advertising support.
F. Other.
1. Grant support.
The Andrew W. Mellon Foundation is particularly well known for its funding for activities such as JSTOR and ArtStor. JSTOR, having been started with Mellon funding, is now an independent not-for-profit institution. Although many other foundations (Kellogg, Soros, and the Packard Humanities Institute come to mind quickly) support libraries, it is not reasonable to expect that operational funding for digital libraries will come from these sources. Some projects are supported by government funding (in the US, typically the National Endowment for the Humanities or the National Science Foundation), but again these tend to be specific research projects rather than long-term support.
2. Cost avoidance.
Many companies have gone to putting information on websites as an alternative to customer service operations. Similarly, much material intended at least partly as publicity or advertising, even if traditionally sold, may well be placed on websites. For example, you can buy the San Francisco Muni Transit map for $2.50, or you can find it on the Web for free. The transit system's finances are based on ridership, not map sales, and they are happy to provide free access to information as a way of encouraging transit use. Similarly many government agencies now publish their information on the Web rather than, or in addition to, printing it on paper; in general these agencies were only trying to do cost-recovery anyway. Some professional societies may turn to free online distribution for similar reasons. This argument, of course, will not apply to commercial publishers.
3. Advertising the print medium.
The National Academy Press has, for a few years, been putting all their new books on the Web for free access, and providing the complete text of each book. To the surprise of many, the result has been an increase in their print sales. Similarly the Brookings Institute has put 100 of its books online free, and the paper sales of those books have doubled. This result is perhaps similar to the experience of record companies, which found years ago that having their records played free on the radio increased disk sales. In fact, recording companies were willing to slip cash to disk jockeys to select their records, producing occasional "payola" scandals.
Web availability has encouraged readership of out-of-copyright items as well. The University of Virginia is distributing almost 7 e-books a minute, with more than 6 million shipped so far (in the first 21 months of operation). Perhaps it is not surprising to see "Alice in Wonderland" and "Huckleberry Finn" near the top of their "best-seller" list; but in one month they sent out more than 2000 copies of the works of Andrew Dickson White. One wonders if he sold that well during his lifetime (although he was President of both Cornell University and the American Historical Assocation in the 19th century).
4. Reputation and publicity.
Just as prestigious publishing arms such as Harvard University Press add to the reputation of a university, a good website may help as well. University libraries certainly compete to have good websites; in fact, this is making some trouble for system design, because of tensions over apparent credit between the library digitizing a work, the library running the web server which has it, and the library portal used by a student. Each participant would like to be perceived as the helpful and important entity; thus there has been a rise of "branding" of university catalogs, for example. I don't know of any example of a library giving its card catalog a "trade name", but we now have all sorts of systems named Melvyl, Hollis, Virgo, and the like.
5. Bounties.
One upon a time, AOL was willing to pay content providers for online content, which they hoped would attract users to their system. These payments disappeared when free web content became available, and were never very large (Time magazine received ten times as much money for advertising AOL to its readers as it got for providing content to AOL users). It seems unlikely that any reasonable business model will be resuscitated from this idea.
6. Dedicated taxes.
In some countries, various fees or taxes are devoted to content production. For example, Germany taxes blank audiotape, and sends the money to the society of composers. The UK has a license fee for television owners which helps support the BBC. One could imagine similar arrangements for online information, whether phrased as a tax on disk drives or modems or whatever. One example proposed in the United States is the suggested "endowment" of the Digital Promise Coalition. It suggests that money from a spectrum sale be placed in a fund whose income would be used to the create or make accessible digital information.
My personal view of the political chances of any new tax or fund in the United States is low. Dedicated taxes are not popular for many reasons, and the collapse of the telecom boom makes spectrum sales less lucrative than previously hoped.
Government financial support in general.
It is more possible that government funding on an national level could support digital information in some way without a dedicated tax or fund. The U. S. government already has such organizations as IMLS (the Institute for Museum and Library Services). The most immediate program of importance is the National Digital Library effort at the Library of Congress. This has a potential budget of $175M and is making plans to expand on the earlier American Memory effort.
Perhaps more important in the long run are activities related to education. For example, the National Science Foundation is investing some $60M to create a national digital resource to support education in the sciences, mathematics, engineering and technology. NSF has also joined with the United Kingdom to support research in the use of digital libraries to teach specific subjects in higher education. In the longer run, the U. S. Department of Education might take an interest in the development of digital techniques for the improvement of education. We do not know yet to what extent the educational applications are going to involve re-use of existing resources, i.e. digitizing material now in libraries, or the creation of entirely new kinds of courseware or other teaching aids.
7. Pledge breaks on the Internet.
Public radio and television are, like the Web, an example of the free distribution of information to citizens. The U. S. does not have a "license fee" for their support, and to make an analogy between digital information online and on the air, one could imagine some variety of online begging. Shareware, for example, works this way. Some libraries do have places on their website where they explain how the public can make donations to encourage the work, but as of now these are relatively low-key, and not very important financially. Again, one is skeptical that this will be an important source of money.
Conclusions
Libraries are facing major changes. Now 84% of libraries have online catalogs of their holdings, and 91% have some kind of electronic reference tools (this may be only a single CD-ROM). The effect of OPACs was first of all to increase circulation, but now walk-in activities are declining as students use the Web. The chart below, taken from ARL statistics, shows the change relative to 1995 in reference queries, circulation, and interlibrary loan. Only interlibrary loan is going up -- these are the requests for things that can not be replaced by local digital copies, since the library doesn't even have a local paper copy. The other metrics are now going down; the additional walk-ins prompted by the online catalogs are now giving way to people who don't come at all because they prefer searching the Web to using print. Librarians noticed that when perhaps 1/3 of their catalog was online, students quit bothering to search the older cards. Perhaps, in the same way, if students can find on the Web 1/3 of what they ought to have for a paper, they will settle for that rather than go to the library.
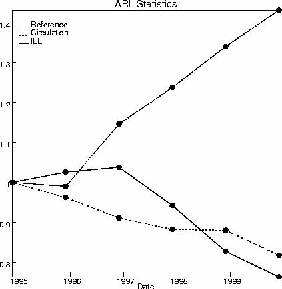
Figure
5
It is likely that there will be a split between the collection of information and the user services (reference, ILL, and simply the provision of reading rooms on campuses) in the organization of libraries. Increasingly, information is likely to come from servers at publishers, societies, and bigger libraries. Some local services, such as circulation and study spaces, are inherently local; others, such as reference, could in principle be remote, and we may see those move to consortia. Corporations sometimes move "customer support" off-shore, e.g. to India. However, few U. S. libraries are owned by organizations that would feel politically comfortable in doing off-shore reference services.
For the primary funding of digital library operations, there seem to be two likely choices: individual purchases and/or community purchases. At the moment, both of these have large resources, which support paper libraries, and which might be redirected.
Libraries are actively engaged in digital library creation. Many libraries have programs for digitizing special collections, such as the Harvard University Libraries with their "digital initiative," a five-year program investing some $12M. The Digital Library Federation combines many institutions with such programs, and encourages the further development and sharing of such projects, paid for out of traditional library resources and research grants.
Many libraries are also creating new material, often as part of university educational programs. One of the most ambitious is Fathom, which is a joint effort of many institutions including in the UK the British Library, British Museum, London School of Economics and the Natural History Museum and in the US Columbia University, the University of Chicago, the University of Michigan, and the New York Public Library. See www.fathom.com for the full list of institutions. MIT's "Open Courseware" initiative plans to make materials used in teaching at MIT freely available around the world. At present, Fathom charges for its material; the MIT site is free.
Perhaps the most direct way in which libraries in general are supporting digital materials is through their acquisitions budgets. The fraction of their expenditures spent on electronic materials is increasing. In 1998 U. S. academic libraries spent $153M on electronic materials and $1363M on paper materials (out of a total of $1.6B), or about 10%. Advanced libraries may be at 30% and specialized libraries, e.g. in biotechnology companies, could reach 80%. The share of purchase funds going to electronics at one library (SUNY) is shown in Figure 6.
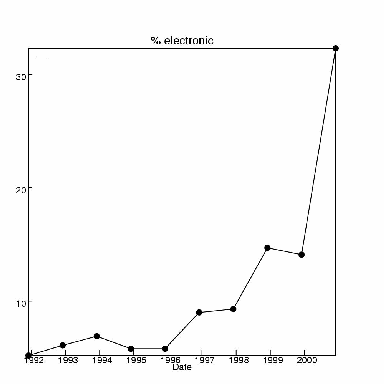
If
institutional libraries are good, multi-institutional libraries may
be better. The arguments that cause university faculty to pool their
needs to gain access to resources also work to suggest that
universities should work together to gain access to even larger
resources. Brian Hawkins suggested some years ago that libraries
merge their purchasing power to gain leverage in the negotiations
over electronic rights, and the United Kingdom has a single
purchasing agent for electronic materials in UKOLN.
An alternative economic model for digital libraries is the direct sale of technical material to individual researchers. The most promising example of a working system so far seems to be the ACM Digital Library. It has both individual and institution subscription rates, has a large number of readers/customers, and could well be the model of a successful future DL system. Another example is JSTOR, which is now financially independent of the Mellon Foundation, but has no individual subscribers; all users are associated with some institution. Neither JSTOR nor ACM, however, have any illusions about getting billions of dollars out of their online services.
It may be some time before the commercial publishers admit that no economic model is likely to make scientific and scholarly publishing as lucrative as video games, and that out-of-print material is mostly worthless. Libraries keep older material around not because it is lucrative, but because it is not.
In summary, what we see today is a mixture of free distribution, library funding, and some individual purchases. We don't know yet whether the future will be dominated by
authors paying, probably by institutions supporting the distribution of their faculty publications;
readers paying through their libraries, with traditional publishers continuing but now delivering electronics;
readers paying individually, so that publishers bypass libraries; or
d) outsiders paying, so that some government agency or foundation provides much of the basic infrastructure and information.
My personal guess is that (d) is unlikely for political reasons, and that (c) is also unlikely despite the success of some professional societies. Whether universities decide that they would, on balance, rather do (a) than (b) is still a tossup. Self-publishing would recover control for the universities, and probably save money (by pushing more work onto the authors); but it would require new administrative and economic structures in the universities. It's a choice between inertia and cost-savings, and so far it looks like inertia is winning.
References
[1]. Library of Congress circulation numbers are in the table on page 1-12 of the Library of Congress Consolidated Financial Statements, available on the web at http://lcweb.loc.gov/fsd/fin/pdfs/fy0101.pdf; the online usage statistics are on the www.loc.gov/stats webpage.
[2]. The chart of web size is a collection of numbers reported by Lycos (for the early years), the group at NEC that monitored web size, and the Internet Archive. See in particular "How big is the Web? How much of the Web do the search engines index? How up to date are the search engines?" by Steve Lawrence and Lee Giles, at http://www.neci.nec.com/~lawrence/websize, which is an updated version of a paper they published in Science ("Searching the World Wide Web",by Steve Lawrence and C. Lee Giles, Science, vol 280, p 98-100 (1998). The chart of disk prices comes from years of buying disks and collecting advertisements.
[3]. Steve Harnad's writings about online publication are available at his website http://www.ecs.soton.ac.uk/~harnad/intpub.html.
[4]. The ARL statistics are at http://www.arl.org/stats/arlstat/index.html in various formats.
[5]. The SDSC number is a private communication from Reagan Moore; the annual report of CRL is at http://wwwcrl.uchicago.edu/info/aboutcrl/ARFY01.pdf, and the price of disk drives is readily available from www.dirtcheapdrives.com. We await the arrival of the already announced 300 GB drives (Maxtor) and the resulting continued decrease of price per byte.
[6]. William G. Bowen, "The Academic Library In a Digitized, Commercialized Age: Lessons from JSTOR," January 2001, http://www.jstor.org/about/bowen.html.
[7]. Matt Richtel, "A Shift Registers in Willingness to Pay for Internet Conent", The New York Times, 1 August 2002.
[8]. Richard Morais, "Double Dutch No Longer", Forbes, 11 November 2002; also see Reed Elsevier's interim report for the increase in ScienceDirect sales: //www.reedelsevier.co.uk/investors/accounts/2002/interim/review/review2.htm.
[9]. Steven Milunovich, "Micropayment's big potential," Red Herring, November 5, 2002.
[10]. M. R. Rose, "2001 was a hard read for e-books", in Wired News; see http://www.wired.com/news/culture/0,1284,49297,00.html.
[11. Steve Lawrence, "Online or Invisible?" available oneline at http://www.neci.nec.com/~lawrence/papers/online-nature01/ or Nature, Vol. 411, No. 6837, p. 521, 2001.
[12]. See http://www.publiclibraryofscience.org.
[13]. See the Internet Advertising Bureau site, quoting Price Waterhouse Coopers: http://www.iab.net/news/pr_2002_12_19.asp.