The Digital Library Federation
Until recently this was known as the National Digital Library Federation,
but it shortened its name (although so far it has not yet
taken in any non-US members). It has fifteen members: Columbia,
Cornell, Emory, Harvard, the Library of Congress,
the National Archives and Records Administration,
the New York Public Library, Penn State, Princeton,
Stanford, UC-Berkeley, Michigan, USC (University of Southern California),
Tennessee, and Yale.
In many cases, the material being digitized is from special collections.
There are several reasons for choosing to digitize special collections
instead of conventional books.
As an example of digitization of non-book materials,
the first project in the Emory University virtual library
listing is a conversion effort for African art images. Other libraries
are focussing on music scores or photographs. Here, for example, is
a photograph from the American Memory Project at the Library of
Congress (Ulysses S. Grant).

Sometimes a digital conversion can not only provide access at a distance,
or access to fragile materials, but actually better access than would
be provided by physical inspection. Here, for example, are three images
of the Beowulf manuscript at the British Library, photographed
in three different ways, as arranged by Kevin Kiernan of the University
of Kentucky:

This manuscript was damaged by an 18th-century fire and then by
an inadequate restoration in the 19th century (predating its preservation
in the British Library). As a result there are parts of the manuscript
which are not readable in normal light today; in some cases they can be
read in one of the digital versions. Since there is no other source
for Beowulf (aside from one copy of the manuscript made before
the fire) these images offers great advantages to scholars.
Of course, this
project is very expensive, and it is not possible to digitize all
materials with the care taken for Beowulf; nevertheless it
shows what can be done when the need justifies the cost.
Another example of a project done by a DLF library which shows economy as well as scholarly advantage is the digitization of Judaica poster material at Harvard by Charles Berlin. In this case some 130,000 posters were digitized via the Photo-CD process and converted to CD-ROM. This allows the originals to be moved to better storage and makes it much easier for scholars to look at these inconveniently bulky items. Conversion was relatively inexpensive, and yet the ability to study these posters has completely revolutionized the attitude towards them by some historians of Israel.
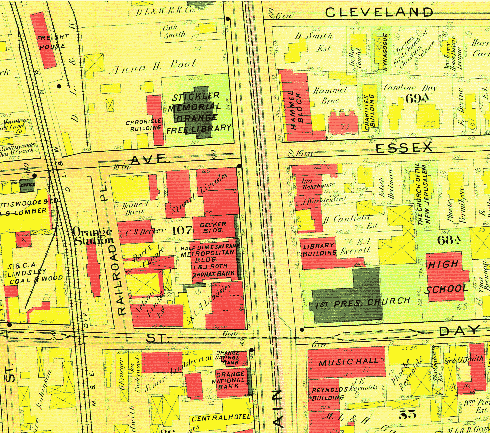
A project which will interest many specialists in local history, genealogy,
and similar subjects is the conversion of the fire insurance map collection
at the Library of Congress to digital form. Fire insurance maps
show every building and its construction; the Library of Congress has
some 700,000 of them.
Here is a sample showing Orange, New Jersey.
Many other institutions are engaged in other digitizations. Here
for example are pictures of a plant record converted by the National
Institute of Biodiversity in Costa Rica and a modern vase made by
Sidney Hutter and digitized by the National Museum of American Art.

One large effort combining Cornell and Michigan is a project called the Making of America, which is digitizing material relating to American history 1850-1900. In this case the source publications are conventional magazines such as Harpers, Scientific American, and Scribners. The effect on humanities research will be one of accessibility to conventional publications rather than introducing unusual material.
The largest project is that of the Library of Congress, which is engaged in a wide variety of collection digitization. Photographs, architectural drawings, maps, sounds, and movies are all included in the American Memory project. Much of this material has been of restricted use because of preservation concerns, and can become much more widely available via their digital library. If one thinks of the Ken Burns television documentary The Civil War as a kind of highlights film of the Library of Congress photograph collection, it will in the future be possible for those who are attracted by it to view much of the remainder of the collection. A particular value of the LC work is the completeness of much of their conversion, in which whole collections are being digitized, as opposed to excerpts requiring users to consult the majority of material on paper anyway.
In addition to the library oriented work, humanists must notice the corresponding activities in the worlds of archives and museums. The Getty Foundation has supported the digitization and use in classes of some 8,000 artwork images under their Museum Educational Site Licensing program (MESL). This is being followed up by two different groups, one centered around art museums and one including historical and specialty museums (the Museum Licensing Cooperative). Archivists, although somewhat short of money, are at least studying the conversion of their catalogs and in some cases the primary materials.
The general impact of the Digital Library Federation in terms of converting material for use by humanities scholars is to extend the kind of material that is readily available for study. For a long time we have found it easier to get printed works than anything else, and true integration of paintings, sculpture, music or other aspects of culture into literary studies has been impeded by inconvenient access. If special collections become more widely digitized, we can expect less sharp boundaries between subjects such as music, theatre, art and literature.
The NSF/DARPA/NASA Digital Library Initiative
There are six DLI projects, at Berkeley, CMU, Illinois, Michigan, Santa Barbara and Stanford. In general, each is looking at new ways of retrieving material. Much of the work is really computer science oriented rather than library oriented, and so few complete collections are being converted. Furthermore, the subject matter covered in the collections used for research are not usually humanities related. Instead, the research in the DLI is valuable for its production of new ways to index and search.
The most library-like project is the one at
University of California Santa Barbara, which is building a collection
of geographically indexed data (including in particular maps and aerial
photographs) relating to Ventura County, California. This project really
is trying to accumulate all information about geography in their area,
and so it does aspire to the kind of comprehensiveness found in
some libraries. UCSB has search
technology indexing by location, and also research on classifying
imagery by content. A sample illustration is shown below, in which
an aerial photograph has been automatically divided into different
regions, with a dictionary of textures shown on the right.

Another project with a geographical area focus and much work on images
is the project at the University of California Berkeley, whose subject
area is environmental reports about California. The Berkeley researchers
are ranging widely over many technologies, however, including ways
of displaying multiple views of the same document or image, and in
particular content-based image search. They have implemented shape and
color searching allowing them to look through images for sunsets, flags,
lakes, and the like. Here, for example, is part of their result from
writing a search routine for objects that look like horses (it does not
always work this well, of course):

The Berkeley collection, although not a traditional library collection and
somewhat fuzzier of definition, is actually large enough to be useful
for many practical applications. After winter flooding last year in California,
for example, people came to the Berkeley project to find aerial photographs
of the areas affected before the inundation.
Carnegie-Mellon University has focussed its efforts on video indexing.
They have a collection of some hundreds of hours of broadcast television
news, which they search using closed-captioned text, speech recognition,
and image searching. For example, they have built image analysis software
which looks for text superimposed on an image and tries then to do OCR
of that text. They also have an algorithm to identify faces and then to
search for matches. The image below shows boxes where the system has
identified a face in the television picture.

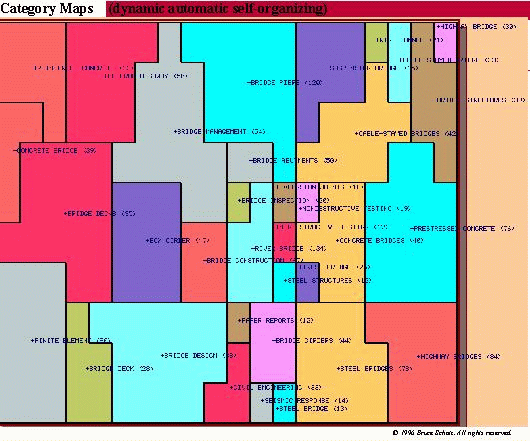
The University of Illinois is looking at scientific journals in
digital form. They are working closely with publishers to build
effective systems for access to primary journal articles in electronic
form. The focus on scientific journals makes this project relatively
more distant from the humanities. However, there are some very interesting
automatic classification algorithms being studied here; the image below
shows an automatic partitioning of a document collection into subject
areas. The use of a two-dimensional representation instead of a linear
hierarchy changes the view of information classification, with consequences
as yet unstudied.
The University of Michigan project subject area is also scientific,
with an emphasis on earth and space sciences. The most relevant part of
this digital library effort
to the humanities is the work attempting to define a set of agents
which can represent user needs. The diagram below shows some of
the agent roles and functions they imagine.
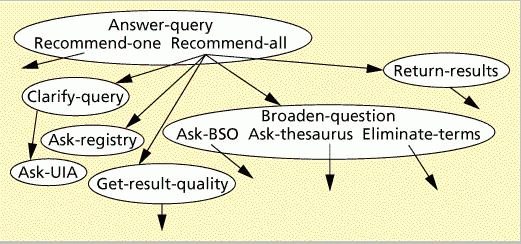
Success in this project might simplify the problems of accessing very
diverse materials, or materials in places which have different
rules for users. Instead of having to learn different procedures for
each collection, agents could handle the economic or technical translations
needed.
Finally, the Stanford project has no actual collection at all. It does
have some very interesting techniques for database merger and rating.
They have studied ways of sending a search to many search engines, which
do not necessarily support the same search syntax or even the same
searching operations. They are also looking at ways of ranking
documents, for example, considering documents which have a great many
links pointing to them as probably more valuable than those with
fewer links.
In summary, most of these projects are of less immediate interest to humanists. They are developing new search techniques that may be very valuable in the future, in particular the ability to search images in artistic or photographic collections. But the actual material studied in these projects is not focussed on the current uses of humanities scholars.
JSTOR
The JSTOR project, now an independent non-profit organization, is not so much a technology project as an attempt to make a self-sustaining digitization organization. With the aid of startup funding from the Andrew W. Mellon Foundation, JSTOR was able to digitize an initial ten journals in both image and text format. They plan to continue with digitizing 100 journals, and to sell these on a subscription basis to university and public libraries. If about 500 libraries sign up, they expect to be able to continue going indefinitely, continuing to scan additional back issues.
The journals were chosen to be of very wide interest, and the scanning is high quality both in terms of the image appearance, and also in terms of making sure that each journal is complete. Libraries often find that their set of some journal is incomplete, with either occasional articles or volumes stolen or missing. The JSTOR set is checked and known to be complete, and it is hoped that at some point libraries will save shelf space by not keeping the original paper versions.
The illustration below, from the American Economic Review, is reduced-size
and thus less sharp than the original JSTOR screen.

In addition to viewing the original page image, JSTOR provides
a complete searchable text of each document, obtained via OCR and
correction.
JSTOR provides desktop access to a wide variety of the backfile of important journals. A particularly interesting aspect of the project has been that many sales have been to small libraries. Originally, the sponsors thought that the most eager customers would be large libraries who owned all the journals on paper and were anxious to save on the costs of shelf space. Instead, many smaller colleges which never had been able to afford these journals found the JSTOR prices so attractive that they have subscribed.
The most important question asked by the JSTOR project is whether their pricing mechanism will suffice to keep the project going. At the moment they focus on sales to libraries, not to departments within universities, and most universities do not additionally charge users within the university. Thus the typical patron in the university sees a great improvement in the service, with desktop access and full free-text search, at no additional cost. Libraries bear the burden of the subscriptions, admittedly at a much lower price than to buy and shelve the paper equivalents, but nevertheless not a trivial amount.
The JSTOR interface is designed to help read the journal articles. Although the database contains the information to answer questions such as ``how many times does the letter q appear in the American Economic Review, year by year?'' the interface does not support that question. Thus JSTOR may avoid some of the complaints that users of machine-readable full text tend towards low level statistical analysis of the texts, rather than a higher level understanding.
JSTOR supplements a existing collections of important primary texts. There are something over 6,000 literary works available online via the ``Online Books Page'' http://www.cs.cmu.edu/books.html including full text of many important authors. Similarly the commercial LiON service of Chadwyck-Healey http://lion.chadwyck.com/ is advertised to contain more than 250,000 texts. However, until now most critical and review material has been missing. The extension of digital libraries into journals and related material offers a new kind of support to scholarship.
JSTOR is a very important economic experiment. It is delivering a large, useful collection of important material, and attempting to do so in a way that will be self-supporting. Many of the other digital library projects are basically supported by research funding and must in the end make a transition to some kind of operational support or they will not be able to convert enough material to satisfy library users. The JSTOR project is the prototype of such a transformation.
Conclusions
The likely impact on humanities research of digital library work is to extend the range of material that is regularly used. The various image processing and image digitization projects will promote the use of visual material. The extension of available material to more journals and more campuses via projects like JSTOR will mean that many more humanists have easy access to a wide variety of critical material. The major need in the humanities is to be sure that adequate amounts of material are converted to machine-readable form under terms scholars or their universities can afford. At the moment too many projects, from the viewpoint of a humanities scholar, are still investigating research in sample collections, rather than comprehensive conversion of the material needed by a practical scholar. Librarians and scholars need to be more active in identifying the material which should be provided in digital libraries and in seeing that it can be made available in an affordable way. Otherwise scholars may feel that digital libraries, although in principle revolutionizing the way work is done, offer great promise but not enough performance.
References
DLI: http://www.cise.nsf.gov/iris/DLHome.html.
DLF: http://lcweb.loc.gov/loc/ndlf/.
JSTOR: http://www.jstor.org.