A Unix system is a good way to implement this software, because of its advantages of easy programming, availability on small machines, and advanced data base routines.
The "New Scientist" published a prediction (in 1964) that by 1984 libraries for books would have ceased to exist, except as museums. [Samuel 1964]. Although this schedule has slipped, we are finding more and more libraries with online catalogs and many online full text data bases are routinely accessed around the world. Unfortunately sometimes users are not happy with the resulting systems. [Borgman 1986]. This paper describes techniques for improving searching in retrieval systems, particularly OPACs (Online Public Access Catalogs).
The queries typed by users to OPACs are often very short; in one experiment an average length of 1.5 words was seen. [Geller 1983]. Users who are accustomed to traditional catalogs, of course, will expect that they can look up only one heading at a time. Simultaneously the document representations, the catalog records, are also very short: a title plus perhaps a few subject headings. Thus automated retrieval suffers, and users who think that an online catalog is a good way to do subject access searching may be frustrated.
Browsing may also be frustrated by some kinds of online catalogs. If the catalog presents only the exact items found, it may be difficult to know what was nearby, or almost found. By contrast it is not possible to look in a printed catalog without seeing the whole page, or to flip through cards without seeing the adjacent cards. An OPAC is more useful if there is some ability to see what was near the sought items, as well as the exact matches to the query.
It would also be useful to have more information about each item. Ideally, there would be a complete gradation of available information from the title to the full book complete with all graphics and illustrations. In reality any addition to the title and subject headings (e.g. the table of contents) would be helpful, but it is not clear when we might get such information.
To return to the problems of short queries, they may be either recall problems (not enough relevant material is found) or precision problems (too much irrelevant material is found). [Salton 1983]. Recall failure normally manifests itself as "no hits" or some such diagnostic indicating that the user's query hasn't matched anything. Precision failure normally represents a huge amount of retrieved material. Efforts have been made to deal with both, since the program can tell which problem exists by counting the number of retrieved documents it is going to display. If that number is zero, it tries to improve recall; if the number is greater than 100, it tries to improve precision.
Traditionally, recall improvement involves a thesaurus. [Salton 1985]. These are made by hand, and involve significant effort to keep up to date. [Humphrey 1984]. Efforts have been made to construct thesauri automatically from a dictionary, e.g. the work done with Merriam-Webster's 7th New Collegiate at IBM. [Chodorow 1985]. However, it is not necessary, and possibly not even desirable, to make a traditional printed thesaurus for retrieval purposes.
To improve recall, dictionary definitions in machine-readable form can be used to expand queries into words, which although not synonyms, are often useful. For example, augmenting "tuberculosis" with "consumption" is sensible with older books; and even adding "native" to a query for "kangaroo" turned out to be valuable (because of books with titles such as "A voyage to New South Wales with a description of the country, manners ... of the natives ..." In addition to various other vocabulary devices (including phrase searching, relevance feedback, and the lick) the system uses a bitmap screen to provide a graded interface from one-line listings, full citations, possibly images of title pages or dust jackets, and complete text where available.
At present the catalog program runs with a subset of 72,000 book records from ESTC. The ESTC office provided a tape of every other record from the file (for security reasons) and I extracted those items which were held by the British Library (so that any book that was in the file would be relatively easy to find, and in an effort to remove some items of low importance).
The program resembles a traditional OPAC, except that it does not prompt
for "kind of search". It merely asks you to type words, and then it
does a coordinate index search through the entire file, for whatever
it can find. Thus, for example, the input
kangaroo
produces the following citation:
T: The voyage of Governor Phillip to Botany Bay;; with an account of the
establishment of the colonies of Port Jackson & Norfolk Island;
compiled from authentic papers, ... embellished with fifty five
copper plates. ...
#: Bound in Kangaroo skin
C: London
I: printed for John Stockdale
D: 1789
O: [2],6,[2],viii,[12],x,298,lxxiv,[2]p.,plates; maps; 4
O: The titlepage is engraved
It is possible, by using suffixes, to select particular fields. For example,
suppose the query word typed is Bromley; this finds 37 items, the
first few titles of which look like this:
A sermon preached at Fitz-Roy chapel, on occasion of the general / Bromley, Robert Anthony / 1789 The state of Bromley College in Kent. / Bromley College; Kent / 1735 A sermon on the nature of subscription to articles of religion;; / Burnaby, Andrew, 1732-1812 / 1774 The mayor, bayliffs, and commonalty of the city of Coventry, / Coventry; Warwickshire / 1721] An accurate description of Bromley,; in Kent, ornamented with views of / Wilson, Thomas, Bookseller, Bromley /Note that these are a mixture of items about the place, those written by someone named Bromley, and those published in Bromley. By specifying bromley/A one requests Bromley in the author field, and gets only 16 items of the 37, some of which are:
An address from a clergyman to his parishioners, by William Bromley / Cadogan, William Bromley, 1751-1797 / 178 A sermon, preached at Fitzroy Chapel, in London: on Thursday the 29th. / Bromley, Robert Anthony / 1798 A philosophical and critical history of the fine arts,; painting, / Bromley, Robert Anthony / 1793-95 The way to the Sabbath of rest:; or the soul's progress in the work of / Bromley, Thomas / 1744Alternatively, one can use multiple query words, which are searched by coordinate indexing (as many words as possible) to produce a shorter output. If one searches lamb, for example, one finds a mixture of cookbooks, sermons on the ``lamb of God'', locations specified relative to a pub named the Lamb, various individuals named Lamb as authors, subjects, and publishers, a song entitled ``Tommy Lamb's cure for a drunken wife'' and other such. But searching for lamb sheep pasture wool yields as the first two citations:
T: Report from the Committee appointed to consider the several laws now
in being, for preventing the exportation of live sheep and lambs,
wool, wool fells, ...
A: Great Britain; Parliament; House of Commons
#: B.S.[vol.38]87
O: Proceedings. 1788-03-05
C: [London]
I: Printed in the year
D: 1788
O: 54p.; 2
O: Issued as a Parliamentary paper
T: Observations on the different breeds of sheep, and the state of sheep
farming, in the southern districts of Scotland: being the result of a
tour through these parts, made under the direction of the Society for
Improvement of British Wool. By Mr. John Naismyth at Hamilton
A: Naismith, John, Writer on Agriculture
C: Edinburgh
I: printed by W. Smellie
D: 1795
O: [4],75,[1]p.; 4
O: Half-title: 'A tour through the sheep pastures in the southern parts
O: of Scotland'
As you can see, the program has various levels of display that it can
show. Titles and citations are clearly the most useful. As a investigation
of the use of graphics, the ability to display dust jackets or covers,
to show book appearances, was included. Figure 1 shows a sample display
(abbreviated for legibility).
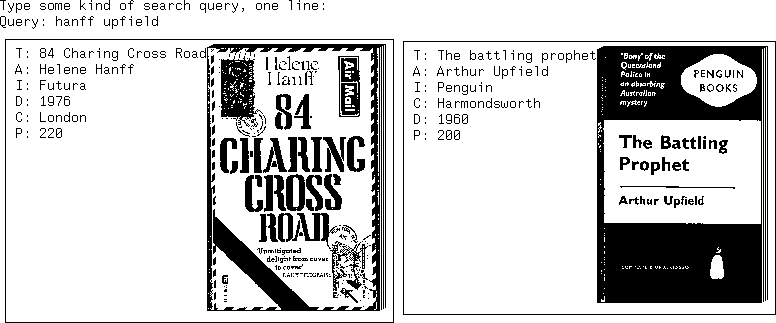 Attempting to use this feature for items such as maps, where it might be
thought that some indication of appearance would be useful, failed because
of the inability to represent enough detail on the screen; see Figure 2.
Attempting to use this feature for items such as maps, where it might be
thought that some indication of appearance would be useful, failed because
of the inability to represent enough detail on the screen; see Figure 2.
 On balance, the comment that the dust jacket pictures use 75% of the screen
space and 95% of the disk space to display no extra information over
the book citation seems valid.
On balance, the comment that the dust jacket pictures use 75% of the screen
space and 95% of the disk space to display no extra information over
the book citation seems valid.
It is also possible, where the full text of the book is stored, to go directly to reading the text. Thus, for Pride and Prejudice the possible levels of output might be:
Pride and Prejudice / Jane Austen / 1972 T: Pride and Prejudice A: Jane Austen I: Penguin D: 1972 P: 398 C: Harmondsworthperhaps a picture of the book, and then
Only two works are available for demonstration in this form.IT is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife. However little known the feelings or views of such a man may be on his first entering a neighbourhood, this truth is so well fixed in the minds of the surrounding families, that he is considered as the rightful property of some one or other of their daughters. "My dear Mr. Bennet,' said his lady to him one day, "have you heard that Netherfield Park is let at last?' ...
Two specific features of the catalog that do seem to work should be
mentioned: term expansion and phrase presentation. In term expansion,
should the user type a word that is not found, the system looks in its
dictionaries and tries to find overlapping words. For example,
cider is defined as fermented apple juice.
Looking for other words defined with ferment, apple, and
juice, the program finds that
wine is
defined as alcoholic drink made from the fermented juice of grapes
and mead is defind as alcoholic drink made from fermented honey
and water. So when there are not enough items found using the
word cider the program expands it to
Query: cider
Expanding to: apple ciderpress ferment juice sour tartar wine mead perry pulque
and then retrieves, for example:
T: A treatise on the culture of the apple & pear, and on the manufacture
of cider & perry. By T. A. Knight ...
A: Knight, Thomas Andrew
#: 988.c.27
C: Ludlow
I: printed and sold by H. Procter; sold also by T. N. Longman, London;
I: the booksellers in Hereford, Leominster, Worcester &c. &c.
D: 1797
O: 162,XXIII,[3]p.; 8
O: With a final errata leaf
T: The true amazons:; or, the monarchy of bees. Being a new discovery and
improvement of those wonderful creatures. ... Also how to make the
English wine or mead, ... By Joseph Warder ...
A: Warder, Joseph
C: London
I: printed for John Pemberton; and William Taylor
D: 1722
O: 16,v-xiii,[3],120p.,plate; port.; 8
O: A reissue of the fourth edition, with a new titlepage followed by
O: 14pp. section 'To the booksellers'
The other problem, that of precision, is dealt with by suggesting phrases. Suppose, for example, one types the word heart as the search term. This would retrieve 145 items. The program prints out a table of adjoining words and asks if you like any of them:
Here are some words that abut the word you used
Can I interest you in or in..
loyal heart (2) heart lover (2)
broken heart (5) heart ache (3)
simple heart (2) heart intend (3)
true heart (4) heart woman (2)
light heart (2) heart trouble (2)
bleed heart (2) heart written (5)
sweet heart (3)
own heart (3)
hard heart (2)
Mark (with right mouse button) or type the words you want added, then hit return
Suppose you mark broken heart, hard heart, heart ache and heart trouble.
This retrieves 11 items. Some of them are what you would expect:
T: The broken hearted lover's garland; containing five new songs. I. The
broken hearted lover. II. The young man's earnest request to fair
Cloie. ... III. The batchelor's lamentation, ... IV. Nell's
constancy. V. The seaman's answer. ...
#: 11621.b.60(5)
C: [Newcastle?
D: 1750?]
O: 8p.; 12
or
T: A cure for the heart-ache;; a comedy, in five acts, as performed at
the Theatre-Royal, Covent-Garden. By Thomas Morton, ...
A: Morton, Thomas, 1764-1838
#: 643.f.7(6)
C: London
I: printed for T. N. Longman
D: 1797
O: 87,[1]p.; 8
but others are perhaps a bit surprising:
T: A rueful story or Britian in tears, being the conduct of Admiral B-g,
in the late engagement off Mahone, with a French fleet the 20. of
May. 1756
#: T.1070(1*)
C: London
I: printed by Boatswain Hawl-Up. a broken hearted sailor
D: [1756]
O: [1],6-15,[1]p.; 8
The Unix system was particularly useful for implementing this system for several reasons. The most important was the existence of many of the utilities needed. For example, some of the large data files (in particular the catalog itself and the dictionaries) need access by each word. So a database library is needed to record the locations in the file of each different word. For this Peter Weinberger's B-tree library [Weinberger 1985]. was suitable, since it handles very large files efficiently, is easy to use and robust, and provides fast retrieval. Other databases, however, did not require quite such flexibility in storage: e.g. the file of the number of occurrences of each word, used to decide on the weighting factor in expansion. So that file was stored using an extensible hashing package by Michael Hawley of MIT, which is more compact than a B-tree. Other experiments were made also: for example, if storage space had been even tighter, there was a system for using compressed bitvectors to provide slower retrieval with less storage overhead. In practice, however, the price of disk space is declining fast enough to make the B-tree system practical. What was particularly convenient about Unix is that all three of these retrieval systems existed with sufficiently similar interfaces and sufficiently small implementations that all could be loaded and the code switched easily from one to another as space or time became critical quantities.
Similarly, it was necessary to have a window manager which could display graphics and multiple fonts on a large screen. Readability is much better on large screens, particularly with a library catalog where one wishes to display as many items as possible. Steven Uhler's MGR manager was very convenient for this. Again, it was not necessary to spend weeks studying the manuals for this system to just get simple pictures of dust jackets and multiple font displays working. And again, there were other window managers that could have been used had this not been available.
From the standpoint of eventual use by a final customer (not yet established, as this is a research project not yet adopted by anybody), it is also an advantage to have implemented this on Unix because of the wide availability of Unix systems on different size hardware. Some libraries prefer large mainframes for their OPACs (often they have them, or have access to them, already for other reasons); some prefer minicomputers; and some hope to implement their catalogs on micros. Unix runs in all these environments and thus eliminates the need to argue about equipment scale.
There were other features tried with less success. These included relevance feedback (it will be necessary to stipulate whether the feedback is on all fields of the citation, or only on the title field), not suffixing the words, and attempting sense disambiguation. The greatest disappointment was that I expected to be able to use the BL pressmark field for searching; having identified one book in a given subject, it would seem reasonable to then browse the shelflist. But the pressmark system was changed over time, and has so many vagaries of use that it would be difficult to explain to anyone what is going on or how to use these pressmarks as subject searches.
It is more important than I originally thought to consider in which field of the record the words appeared. There were a surprising number of strange retrievals caused by comments on binding, printers names, and the like. This is, I suspect, a property of the loquacity of eighteenth century title pages and would be less serious with modern records.
The lessons from this work are that (a) it isn't all that difficult to produce a demonstration of an online catalog; (b) it is useful to try term expansion; the next step should be use a thesaurus in addition to, or in place of, a dictionary; (c) it is useful to dynamically present possible phrases; and (d) dictionaries can help with the problems of vocabulary shifts over centuries. And, it is convenient to use a Unix system for developing this sort of program. I await the OED in machine-readable form to do a better job at all of these issues.
This appendix is only of interest to a potential user.
To run the program on Unix, make a fairly large window and type gcatl [files]. At present it is a rather flakey program, and it assumes that various items are in special files, but it does work well enough to do these examples. The default (no files listed) is the twenty books with a few dust jackets file. Normally it is run as gcatl -e -p -f3 estc.? where the estc.? selects the seven separate files comprising my half-set of BLESTC. The other options make the font smaller, select term expansion, and select phrase proposing. The program expects all its files to be in, or linked to, the directory /usr/lesk/pageimages for the catalog items and /usr/lesk/dicts/oaldce for the dictionary files. Here is a list of all the possible options for the program.
There are various other options that are not working well enough to mention seriously, or for other reasons are undesirable for ordinary users:
[Borgman 1986]. C. Borgman Why are online catalogs hard to use? Lessons learned from information retrieval studies. J. Amer. Soc. for Information Science (November 1986).
[Chodorow 1985]. M. Chodorow, R. Byrd, and G. Heidorn; "Extracting Semantic Hierarchies from a Large On-Line Dictionary," Proc. 23rd Annual ACL Meeting pp. 299-304, Chicago (1985).
[Geller 1983]. V. J. Geller, and M. E. Lesk; "An Online Catalog Offering Menu and Keyword User Interfaces," Proc. 4th National Online Meeting pp. 159-166, New York (April 1983).
[Humphrey 1984]. S. M. Humphrey; "File Maintenance of MeSH Headings in MEDLINE," J. Amer. Soc. Inf. Sci. 35 (1) pp. 34-44 (1984).
[Salton 1983]. G. Salton, and M. McGill Introduction to Modern Information Retrieval McGraw-Hill (1983).
[Salton 1985]. Inspec Thesaurus IEE (1985).
[Samuel 1964]. A. L. Samuel The banishment of paperwork New Scientist (27 February 1964).
[Weinberger 1985]. P. J. Weinberger Unix Programmer's Manual, Eighth Edition AT&T Bell Laboratories (February 1985). See section cbt(3).