Some pharmaceutical libraries, for example, are spending more than half their acquisitions funds on electronic sources.
Thank you for inviting me to your round table, and I am very flattered to be here in Kanazawa. I will talk on how I see value coming from digital information, and what kinds of changes I see coming about as a result. To summarize in advance,
The most important question we must answer is how we will build a self-supporting system of digital information, in a world in which libraries will need to cooperate more than they ever have in the past. In the digital world, it matters much less what libraries own and possess on their own shelves. It matters much more what they can access for their patrons. So libraries will be sharing the provision of information, and will have to trade a great many services among themselves. How will we be able to arrange things so that libraries can cooperate, rather than fight each other for patrons? How can we establish the value of librarians and library services?
All libraries are under pressure as the costs of journals increase. The Mellon Foundation has prepared studies showing that between 1970 and 2000 the typical US academic research library will lose 90% of its purchasing power [Cummings 1992]. The state of California went from over 100 hours of public library opening per 1000 residents to under 50 hours from 1977 to 1993. Electronics offer several ways in which libraries can improve service while reducing cost. For example, fax machines have already made it more practical for libraries to buy copies of single articles on demand. But digital storage carries with it even more advantages of service, and now looks as if it is about to offer cost benefits as well. Libraries may have looked the same for many centuries, but the changes under the surface are about to erupt onto the users.
In fact, the use of author-generated electronic information is growing rapidly in many areas without much if any involvement of libraries, but rather thanks to the Internet. There are over 100 electronic journals now; one of the best known is Psycoloquy, edited by Steven Harnad. Andrew Odlyzko has written an important paper arguing that traditional journals are likely to be replaced with all-electronic versions [Odlyzko 1994]. Perhaps the most dramatic example of the importance of these bulletin boards is the High Energy Physics bulletin board run by Paul Ginsparg at Los Alamos. This is now one of the most common places for physicists to find out about new ideas. When Ginsparg found himself overwhelmed with clerical work, and withdrew the service, physicists everywhere protested, and did so loudly enough to get help assigned by the Los Alamos management [Taubes 1993].
Although some of the interest in online information is in its instanteous availability, one of the most important advantages of digital libraries is searching. When full text data bases are available, any word or phrase can be found immediately. As I will discuss later, this makes several kinds of digital library tasks faster and more accurate for library users. In addition, digital storage means that items are never off-shelf; it means that a copy is as good as an original, so there is no need to worry about deteriorating physical media; and it means that a copy can be electronically delivered across campus as easily as within the library. Libraries need no longer define their patrons as people who walk in the door.
All of this has been true since computer storage began to be used in libraries. Now the rapid declines in the cost of computer equipment, combined with the steady increases in the costs of buildings and staff, are about to make digital storage economical even for older materials. In the CLASS project at Cornell, scanning an old book cost a bit over $30 [Kenney 1992]. This was for material that is sufficiently fragile to require placing each page on a flatbed scanner. Paper strong enough to go through a mechanical feeder can probably be scanned for 1/4 that price. The cost of the disk space, even continuously online disk, to hold the scanned pages of the book, is under $10. The disk drive industry will ship 15 petabytes this year, or 2.5 megabytes per person in the world! The magnetic tape industry will ship 200 petabytes of blank tape, enough to hold the entire Library of Congress ten thousand times.
Meanwhile the cost of building bookstacks in libraries continues to increase. Cornell has recently finished a stack that costs $20/book. Berkeley is building one at a price of $30/book. The University of California San Francisco, which has to face not only earthquake-resistant building but a complex and cramped site, is building a library at a cost of $60/book. And, of course, the new British Library is about $75/book and the new national library in Paris (the Biblioth\o'e\(ga'que Nationale de France) will cost about $100/book. Admittedly the last three prices include considerably more than just a bookstack, such as reading rooms and offices. Nevertheless, we are already at a stage where a library might seriously balance building a central campus stack against scanning a few hundred thousand out of copyright books.
A library can do much cheaper with the `Harvard solution' of an offsite depository, built out of sight where land is cheap and architecture is unnecessary. The Harvard Depository costs perhaps $2/book to build, but incurs both the cost of shuttling books back and forth to the users, and the service penalty of not having the books immediately available (nor browsable). The shuttling cost, however, is such that Don Waters of Yale has estimated that within ten years digital scanning will be a cheaper solution than offsite storage. For many libraries, e.g. corporate libraries, offsite locations are not used and whatever storage is used is charged at full office building rates. These libraries have even greater incentives to substitute electronic documents for paper (and are more likely to be able to do it, since they normally have more current material that is available in machine-readable form).
Returning to the preservation model, if several different libraries all need to have the same books scanned, there are additional economies. As with microfilm, doing the conversion once and then sharing the results among several libraries is a great cost saving. The Mellon Foundation is funding project JSTOR, in which ten economics and history journals (5 of each) are being scanned as a way of seeing whether a great many libraries can all save some shelf space by using the electronic copies. Another project at Cornell is scanning the world's agricultural literature up to 1950, not so much to save shelf space as to permit its distribution to libraries that don't have copies. Both of the projects are careful to obtain copyright permission for every work still protected.
There are other projects doing scanning not to save money, but to improve access. Particularly valuable or particularly fragile manuscripts may be scanned to let scholars see them without risk of damage. The British Library, for example, is involved with scanning both the Beowulf manuscripts (stored at the University of Kentucky) and the Canterbury Tales manuscripts (with Oxford University). These projects demonstrate that scanning, under different kinds of light illumination, can show features of the manuscripts more easily than simple visual examination in ordinary room light [Robinson 1993]. On a larger scale, IBM is scanning both many manuscripts from the Vatican library, and the archives of Spanish documents about the Americas in Seville. These materials will now be available around the globe instead of only to those who can travel to them.
Of course, the scanning costs of old material, and the disk storage, are only part of the costs of building a digital library. There needs to be an infrastructure of terminals, networks, and people to support them (and help the users with difficulties). Fortunately, this material is arriving in libraries for other reasons. The switch to online catalogs has brought computers and networks into many library buildings, and the for-profit information services are expanding them. Traditionally, libraries have relied on the general commercial marketplace for most of their technology, and just as librarians find themselves wanting a way to get the infrastructure to support preservation of old material, it is arriving in the form of the businesses involved in distributing new material.
The idea of information delivery as an industry is very new. Yes, there were for-a-fee lending libraries in 18th century England. For most of the twentieth century, although books were sold libraries normally did not charge their patrons to read them. And in fact there are still many librarians who view this as a principle, and argue strongly that in most organizations information should be free. There is a saying among chemical information specialists that a month in the laboratory can save you an hour in the library. So, businesses should not want their employees to hesitate to look up information. However, as new kinds of information became available, it became common to charge for them. United States corporations want to treat all operations within themselves as businesses, and furthermore the first text retrieval systems were so expensive that they could not realistically be made available free.
Information retrieval is now a rapidly growing industry. In the United
States, the electronic information industry had revenues of about $15.6 billion
in 1994, and grew 16% from 1993 [Hillstrom 1994].
Of this, about 2/3 is from online, an eighth
from CD-ROM, and the rest from tape sales or other media. CD-ROM is growing
fastest, doubling each year through the early 1990s.
Time-Warner has estimated a US market of $400B/yr for the ``information
superhighway'' products.
Since everything being printed today passes through a computer,
we can capture it for later computer distribution. Thus, there is
now an enormous business in Ascii information distribution.
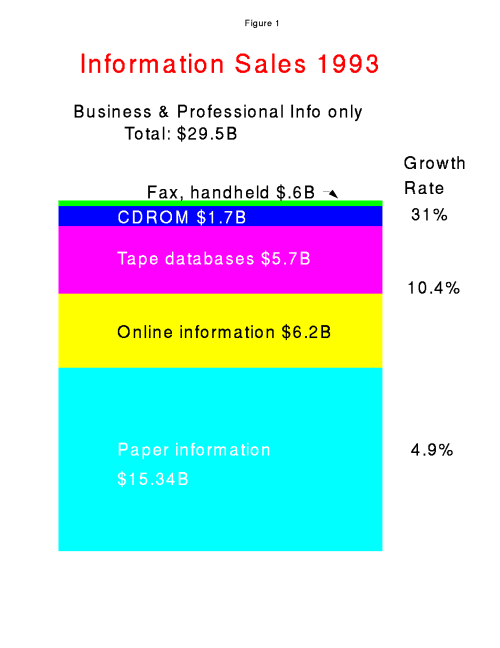
Figure 1 shows a breakdown of part of the information business; note
that paper information (books, newsletters, etc) is now only comparable
to electronic sales, not larger.
Some pharmaceutical libraries, for
example, are spending more than half their acquisitions funds on
electronic sources.
Online, there were 2.8 million business subscribers and 3.4 million consumer subscribers in 1993. And the growth rate here is also rapid. Business subscribers grew 25% in 1993, while consumer subscribers increased 44%. About 30% of the sales of US online services are to non-US customers. The industry employs about 45,000 people in the United States. In fact, if one combines the software, data processing, and information retrieval industries, these companies employ more people than automobile manufacturing.
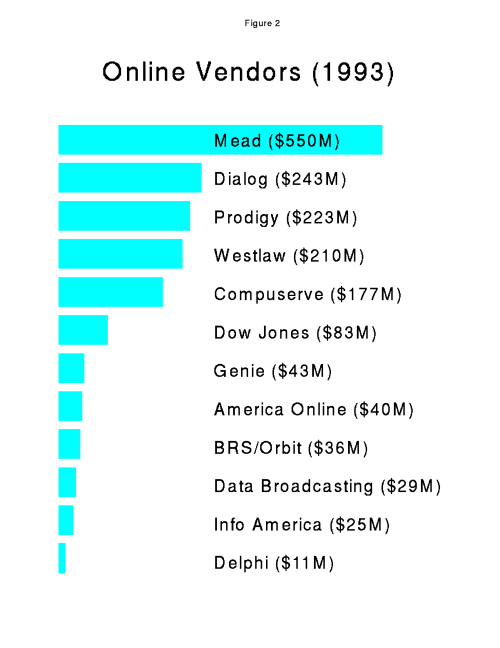
Most of the companies making a lot of money selling online retrieval are selling to businesses. Dun and Bradstreet sells over $1B worth of online retrieval a year, and companies such as Dow Jones, TRW, and Trans-Union Credit also sell hundreds of millions of dollars in financial data. In what we would consider the library world, the biggest suppliers are in the legal information business. Table I shows the largest online vendors (also Figure 2) [Rodriguez 1995].
Table I
Information Vendors (1993)
Revenues Company
$550M Mead Data Central (Reed Elsevier)
$243M Dialog (Knight-Ridder)
$223M Prodigy (IBM, Sears)
$210M Westlaw (West Publishing)
$177M Compuserve (H&R Block)
$83M Dow Jones News Retrieval
$43M Genie (GE)
$40M America Online
$36M BRS/Orbit
$29M Data Broadcasting
$25M Info America
$11M Delphi (Newscorp)
Text retrieval software by itself is about a $500M business. Table II shows the growth of the business (from Interactive Age, July 31, 1995):
Table II
Text Retrieval Market
1990 $80M
1991 $175M
1992 $232M
1993 $303M
1994 $385M
1955 $506M*
1996 $658M*
* Forecast.
There are over 100 companies supplying text search or browser software
(including Bellcore's SuperBook software). The largest companies in
the business are shown in Table III.
Table III
Text Search Companies
Company Market Product
Share
Dataware 8% BRS
Information Dimensions 7% BASIS
Fulcrum 6% (OEM supplier)
Verity 5% TOPIC
Zylab 4% ZyIndex
Intext 4% WebPak
Folio 3%
Electronic Book Technologies 3%
Excalibur 3%
CMTG 3%
other 54%
Note that the business is dominated by small companies, with no single
company having even a tenth of the business.
There is also, of course, a large free information distribution system online, the Internet. At present growth rates every human will be on the net in about 2001. The very disorganization of the net makes it difficult to know how much information is out there. Lycos has found over 5 million documents, but they vary enormously in size, and there might be four times as many pages inside corporations or otherwise hidden. Perhaps the entire net might contain 20 gigabytes of information, of extremely variable quality. Netnews is distributing about 140,000 articles per day containing 450MB. In 1993 this number was 50 MB and in 1989 it was 1 MB. Unfortunately five of the six largest newsgroups are still obscene pictures. The net in general is doubling each year, although the largest single traffic source is still ftp (file transfer). Many companies are now setting up to sell Internet-based information.
Note the enormous difference between what is transmitted and what is kept. If the estimate of 20 GB is correct, a mere 40 days of netnews would accumulate that much material. However, much of netnews, often called ``netnoise,'' is so low quality that nobody would want to save it. Although the availability of pictures and sounds on the Web means that Web pages can be comparable or superior in attractiveness to traditionally published material, the lack of quality control on what appears often leaves searchers frustrated. And the lack of institutional responsibility means that something which is there today can be gone tomorrow. We used to say that if a million monkeys sat at a million typewriters, they would eventually write all the works of Shakespeare. The Internet has proven this is not true.
In short, a wide variety of modern information is being distributed digitally. Some is part of a for-profit information business; some is part of a free distribution system dependent on volunteers. Libraries are a major part of this system, and they can use much of the same infrastructure to support both this new digital content and the material they might convert from their past files.
Should we be encouraging the rapid substitution of computer storage for books? Some users are emotionally pleased by the feel of a book (in interviews at Cornell some chemists asked about their use of journals claimed they even liked the smell of the journals, which is only modern PVA glue). They resent the idea that more and more reading will be from screens. Certainly paper is more portable; we do not yet have radio Internet links in sufficiently common use to let people connect to a library from a laptop. Some users argue that reading from paper is easier, more efficient, more accurate, or otherwise better. If reducing library storage costs was all that mattered, microfilm would have triumphed a generation ago.
A choice also has to be made between data bases containing searchable Ascii, derived from the original printing process, and those containing page images, derived from scanning the output pages. Some services, such as the online newspapers of Nexis and Dialog, or the various full-text encyclopedias and medical journals, are based on Ascii. Full text searching is available, and the output can be clipped and pasted into files. On the other hand, illustrations are missing. In some cases, such as the Chadwyck-Healey English Poetry Database, there were few illustrations in the originals anyway. In others, like the Perseus CD-ROM of ancient Greek, illustrative material has been added separately. In many cases, however, as in the online publications file of McGraw-Hill publications or the journals in STN (Science and Technology Network), the illustrations are simply missing.
Other services, such as the Adonis disks of medical journals, the UMI disks of IEEE publications, or the Elsevier TULIP program, rely on scanned page images. Typically these are distributed on CD-ROM, which solves the problem of network capacity as well as making it difficult for people to make illegal copies. The full page is available with pictures; but to read the text easily requires a high-quality screen (so these services rarely distribute to the desktop) and searching is usually based on a traditional indexing service, rather than full text. In the list above, Adonis relies on Medline, UMI on Inspec, while the TULIP system does provide full-text searching, but it is based on OCR and is not shown to the users directly [McKnight 1993]. Systems that rely on OCR can not, today provide the same quality of Ascii text that can be derived from production processes. Even though AT&T's Red Sage project has tried to provide such services as highlighting hits even while using OCR to get text, it will start using Postscript files as they become available [Hoffman 1993].
The CORE project set out to examine the relative effectiveness of Ascii, image and traditional paper [Lesk 1991]. The full project converted approximately 300,000 pages of primary chemical journals published by the American Chemical Society (ACS), providing both scanned page images and accurate Ascii, derived from the ACS database and converted to SGML. This is one of the few projects which had both image and clean Ascii for the same material. It was a joint effort of Cornell University, the American Chemical Society, Bellcore, Chemical Abstracts Service, and OCLC. A copy of the file is at University College London where additional experiments are run.
In our test environment, in which our users are chemists. They are very visually oriented; the ACS journals are about 1/4 illustrations (counting by square inches of paper). These illustrations are usually line drawings; they are chemical structure diagrams (schemes), spectrographic charts, and drawings of apparatus, among other things. To permit the users of the Ascii file to see these, we sort the page images into textual and non-textual material, and make the schemes and figures part of the file. We can, fortunately, obtain the tables and equations from the ACS database. These, even if clipped as ``non-text'' by the page analysis routines, are presented to the user in a form derived from the Ascii data, not as images.
Several different interface programs have been written to display the chemical data. In all cases users can do a full text search on the Ascii data; the programs differ in their search algorithms and in their screen management. Figures 3 through 5 show these interfaces.
The page image interface,
Pixlook, is shown in Figure 3.

The mode shown is the ``browsing''
mode, in which the user sees a list of 20 journal names (the middle
window on the left side) and starts by choosing a journal.
The user then picks a year, and issue, and is shown
a list of titles of articles in that issue (lower window on left side).
Clicking on a title (in this case ``Fiber-Optic ...'') will
bring up the page. The largest window shows the page, in this case
Analytical Chemistry, vol. 65, page 2330.
The original scanning is at 300dpi bitonal, but
to get the image to fit on the screen it is reduced to 100 dpi with
the introduction of greyscale to improve readability. The user can
click on the ``expand'' window to see full resolution, but then only
a small part of the page can be seen. Even with these dodges, we
insisted that the participants in our trial have larger than normal
screens on their desktop machines (800x600 minimum). Searching in
Pixlook is by text word, with suffixing and fields (author, title,
etc.). A separate window (not shown to reduce the complexity
of the figure) handles the searching, and then the user gets
a similar display of titles. Since this is
an image interface, nothing is done about highlighting hits; the user
must scan the article looking for the exact place where something
was matched.
Figure 4 shows the first of the Ascii interfaces, SuperBook.
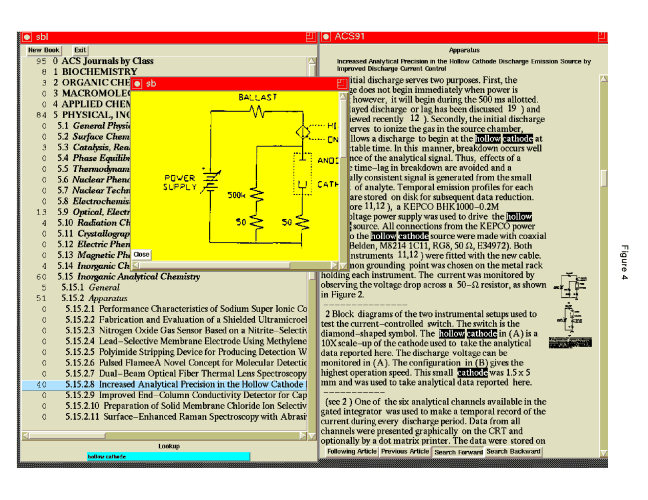
SuperBook emphasizes user positioning as its main feature. Unlike
hypertext systems with arbitrary jumps from one item to another, or
even systems which would view the chemical documents as a collection
of articles, each independent, SuperBook believes that every document
collection is a linear string. Thus, the user can always view
one item as before or after another, and is less likely to get lost.
A table of contents, arranged hierarchically, is shown on the left
side of each page, while the text is shown on the right.
The table
of contents is labelled with the number of hits in each section.
The number of hits is shown to the left of the section titles.
Thus, in this case the user has searched for ``hollow cathode.'' There
were no hits in Macromolecular Chemistry, and only 3 in Organic Chemistry.
As expected, these words appear most frequently (84 times) in the large section
of Physical, Inorganic and Analytical Chemistry. This category is expanded
in the display, and 60 hits are in the section on Inorganic Analytical
Chemistry, and under Apparatus an article is found with 40 hits.
The user selected that particular article (``Increased Analytical
Precision ...''), and the actual instances of the words are
shown in the text page.
One disadvantage in our context is that figures, along with footnotes, tables, and equations, are not immediately presented to the user. Instead, they are indicated with symbols in the right margin of the text, and the user must click on them to see the item. Upon such a click, the item pops up in a new window. To help the user choose what picture to view, it is shown in the margin as a thumbnail; but footnotes, tables and equations are only icons. The searching method in SuperBook is without standard Boolean operators: the use of several words in a query automatically means ``co-occurrence within a paragraph.''
Finally, Figure 5 shows the Scepter interface, built by OCLC.
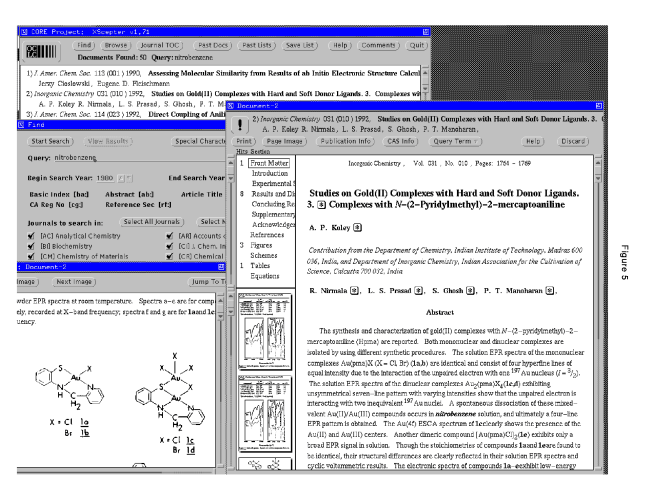
Scepter
uses Boolean searching, with fields, and uses various menus to select
date ranges, which journals to search, and so on. Scepter responds
to a search with a list of hits, and then the user selects an article to read.
In this case the search was for ``nitrobenzene'' and the 50 responses are
presented in the top window (which can be scrolled or enlarged
to see all of them). The user has selected a particular article
on ``Studies in Gold(II)...'' and Scepter displays
a menu of parts of the article. The user may choose to view the
text, the figures, the references, or whatever. The figure list is
shown as a series of thumbnails; and in fact viewing the figures is the
first thing users wish to do. The chemists are visually oriented, and
find the pictures the most valuable part of the article. The actual text,
as in SuperBook, is synthesized and reprinted rather than shown as the
page image. This makes it easier to read. The figures, as shown at the
bottom left, are viewed as bitmap images. The user preference for
viewing pictures was so extreme we joked about producing a hitlist
in which only the author and the pictures were shown, to be called the
``comic book'' version of the journals.
There is no space here to review the entire CORE project, but it may be interesting to refer to an experiment done to compare the effectiveness of paper, image and Ascii interfaces. In this experiment Dennis Egan and collaborators used a file of 12 issues of the the Journal of the American Chemical Society (just over 4000 pages or 1000 articles) [Egan 1991]. Thirty-six chemistry students from Cornell University were divided into three groups; one group had the journals on paper, with Chemical Abstracts for searching, the second used the journals on SuperBook, and the last with Pixlook. Two chemistry professors created a set of tasks, of five different types, intended to represent the kinds of things that chemists do with library materials. The tasks ranged from fairly easy ones (finding a specific fact in a known article) to quite difficult (recommending a synthetic pathway for an organic chemistry transformation). Each student spent six hours doing examples of the five tasks.
The five tasks differed in their dependence on searching. The simplest task had questions such as the following: ``In the article `Total Synthesis of Ginkgolide B' by E. J. Corey, M. Kang, M. C. Desai, A. R. Ghosh and I. N. Houpis, {\em JACS} v. 110, p. 649-651, what is reported as a medically important property of ginkgolide?'' The user is suppliedly with the exact citation of the article to be read, and must just go off and spend the approximately five minutes required to read the article looking for this fact. Alternatively, another task has questions of the form ``What is the calculated P-O bond distance in hydroxyphosphine?'' in which the user must find the article.
The results show that for the tasks in which no searching is required, the electronic and paper systems are comparably effective. Most students can do the problem correctly and their times for reading are comparable. But for the tasks involving searching, either of the electronic systems is both faster and more accurate than paper browsing. In fact, the majority of the students faced with searching through paper for answers to such questions gave up, unable to complete the exercise. This confirms earlier experiments with SuperBook, in which students asked to look for things with paper in a textbook were both 25% faster and 25% more accurate using SuperBook than using the textbook on paper. Whenever it is necessary to search for something, electronic systems are much better than paper. When it is only necessary to read, electronic systems with large screens can provide equal reading speed as paper, as previously shown by John Gould.
Thus, as libraries move to more electronic information, we should expect users to do their work better. Although there will be some people who object to the change, most will probably find the migration to their benefit. Yes, there will be those who complain that they can not easily carry information home; but there will be others tickled pink to get information directly on their desktop. OPACs are probably a good model; there have been a few mournful users regretting the loss of the card catalog (including one particularly unfortunate and error-ridden article by Nicholson Baker in a 1994 issue of The New Yorker), but most users have been happy to have the improved searching abilities of the computerized systems. The same response is being observed to full text on computers, and it is not uncommon to see email questions now requesting online sources only as answers.
If we look at the traditional research areas of information retrieval, they have been focussed on text searching. Innumerable papers have been written on ranking, probabilistic retrieval, term weighting, vector space models, and other techniques for searching for queries phrased in words. What is remarkable is that few of these have made it into practical systems. Many of the online systems still use Boolean searching and other technologies from decades ago. Nor, if one reads the advertising for the online systems, do search algorithms seem important.
Part of the problem is that there is such wide spread in performance over different queries and documents. Experiments often fail to show statistically significant differences between methods, because there is so much variation among queries. The best experiments, running on several gigabytes of text, are the TREC (Text Retrieval Evaluation Conference) series. In these experiments, it is still found that retrieval quality varies widely across queries. Among the systems that are leading in performance, they perform better on different queries. And even among the systems leading on the same queries, they achieve their results by retrieving different documents. With this much scatter, users fail to see reliable differences among systems.
What this means is that it is probably time to move on from algorithms which simply count words in different ways. Instead, we must face the very large quantity of image and sound information which people wish to retrieve. It is now easy to record radio programs in digital form and create an archive that it would be nice to search; it is becoming straightforward to create video archives in digital form, although still a bit expensive. However, we have little in the way of automatic techniques for searching images and sounds. Traditionally librarians have indexed pictures by writing textual descriptions of them and then processing the descriptions as typical pictures. This is too time-consuming to do now, and as digital cameras create vast quantities of pictorial information in machine readable form, it is not likely to become easier in the future. The Library of Congress has 9 million photographs in its collection; as they are scanned, it is not possible to imagine all of them being cataloged individually. New research is needed in this area.
For example, consider the six projects funded by the Digital Library Initiative in the United States (NSF/NASA/ARPA). Four start with more or less typical collections of paper based information (scientific journals in Illinois, earth and space sciences in Michigan, environmental reports in Berkeley, and computer science literature at Stanford). Every one of these has gone on to add additional, more unusual kinds of information. Michigan, for example, includes substantial videoconference material related to world-wide geological experiments. The remaining two projects are unusual: UC Santa Barbara deals entirely with maps and images, while Carnegie-Mellon's collection is videotapes.
To be specific, I do some radio recording purely for personal
convenience. News programs are recorded from radio stations in both
the US and the UK, transmitted to one terminal, and listened to at
the user's convenience. This is easy enough that it can be set up
even for one person (which conveniently brings the operation within
the scope of time-shifting fair use in the United States, I believe).
In terms of maps,
Figure 6 shows some sample image data: old and new maps of Cranford,
New Jersey, along with satellite and aerial photography.

Such information
can be used for marketing, urban planning, network design, and other
applications, but not easily if the systems to access such data presume that
everyone trying to use it is a specialist in space-based photographic
information.
In the past, the problem has been that image analysis programs were very specialized. Collections of maps, of faces, of aerial photographs, of CAD drawings, and so on have all been handled with software tailored to the kind of material. Only recently, with research such as the IBM QBIC project, have we seen ways of handling images in a completely general way [Niblack 1993]. Additional research in techniques for handling non-standard information is needed. Griffiths reports estimates that reading in the United States, even by professionals, has declined about 10% in recent decades, presumably as a result of television and other media [Griffiths 1993]. As people depend more and more on non-textual information, we need to build systems that can index it and use it. You may have some more time; the same decline is not apparent in Japan.
Other techniques for finding information without traditional text search include community recommendations. Bellcore [Hill 1995] has developed an efficient way to suggest movies. A group of people watch and rate movies, and the computer can find, for any individual, a model in terms of the ratings of other individuals. As an example, the judgments of movies made by person A might be modeled by looking at the average judgments of B, C and D. Then, the system can find movies that B, C, and D liked, but that A has not seen, and suggest that A will probably like them too. This turns out to be more accurate than relying on the recommendations of movie critics, since it gives individually tailored recommendations, rather than having to give only one opinion to all possible viewers.
In summary, we need ways of finding new kinds of information and new ways of finding the old kinds of information. The world is converting from text-based computer interfaces to ``multimedia'' systems. New searching modes, whether they be intelligent image understanding, fast picture browsing, or community recommendations, can be the basis of entire industries of tomorrow. Certainly everyone where I work noticed the initial stock offering of Netscape, which was valued at over $2B despite the fact that searching and buying things on the Net is still not really a business as opposed to an amusement. The attractiveness of the new technology for viewing and reading is bringing in millions of users, and we need to see that they are not disappointed by their inability to wade through the piles of material that are also accumulating.
So far, I have explained why more and more information should be and will be available online. What does this mean for libraries? If every student in a college, or every corporate employee, is going to get the information they need directly on their desk, what happens to the traditional library organization? Information vendors are thinking of bypassing libraries, for example. Will they succeed?
Figure 7 shows the breakdown of costs associated with putting a book
into a typical U. S. university.
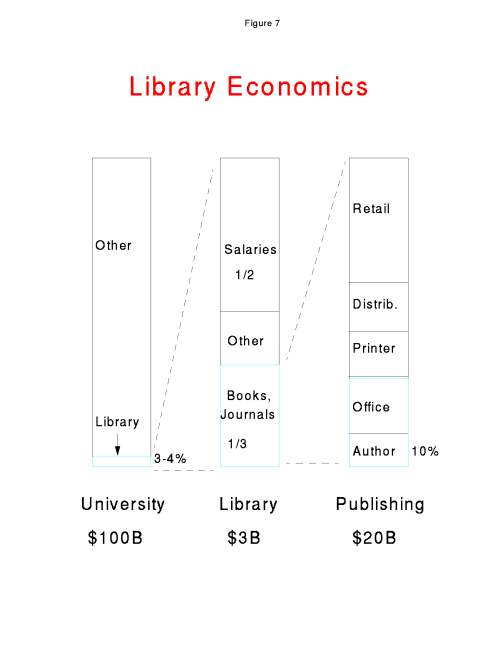
As can be seen, relatively little
of the money spent on the library by the university is going to the
author (despite the fact that most universities do not monetize space
and properly account for the library buildings).
Admittedly, the library is providing other services besides
putting books on shelves; it may, for example, be the only quiet place
on campus to study. But it is very tempting for a publisher or even
an author to think of providing direct access from student workstations to the
source material, eliminate a great many of the intermediate costs associated
with bookstores, book wholesalers, and libraries, and collect greater revenues.
Online books have other attractions for publishers; new editions would
be easy to bring out, there would be no second-hand copies to sell, and
so on.
This reflects the ease of transmission of digital material. The reader does not care where the original copy is stored; it could come from a local library, a bookstore system, a publisher's databank or a distant university. Thus there is a potential for great competition between these organizations. If, someday, a student at a small college in the United States can access any book in the Berkeley library from the student's dorm room, why does the small college need a library? The administration of the college will not be allocating funds to pile up books in a large building if nobody ever reads them.
Libraries were once relatively self-contained organizations. Many major research libraries in the United States had their own classification schemes, and even inter-library loan was a slow and infrequently used procedure. In recent decades this began to change, as organizations like the Research Libraries Group and OCLC encouraged shared cataloging and shared purchasing of lightly-used resources. Within large universities, networking of CD-ROMs has replaced (where possible) buying multiple copies. More and more, libraries have learned to share, as a way of coping with increasing costs in a world of financial pressure upon universities and, for that matter, upon corporate libraries.
Now, we probably either face much more cooperation, or much more competition. Everyone views the delivery of information to the desktop as their opportunity: this includes traditional libraries and publishers, bookstores and wholesalers, telephone and computer companies, and new startups addressing this market. What will be the effect of the new technology on concentration in the distribution of information? Traditionally, economies of scale lead to concentration: there are more authors than publishers, more publishers than online services. Will the Internet mean that we increase or decrease diversity of authorship? This is not yet clear, and depends to some extent on how we manage the availability of servers and browsers. We need to have open protocols for server/browser connection, and an economic system in which it is possible for small publishers to deal effectively with small customers.
Universities, meanwhile, must re-think the role of the library. Unfortunately, many American universities rate their libraries by counting the books they hold. The other services libraries perform, such as guiding students to information and training them in the use of information resources, are not valued appropriately. In these circumstances, as digital technology makes libraries particularly vulnerable to the idea that they could be ``outsourced,'' we can expect to see universities urging additional budget cuts upon their libraries. Libraries can not value themselves either in terms of the books they own or the count of people who walk in the door, the only measures it has been easy to get in the past. Instead, they must take a larger role in education generally.
In fact, the most critical function universities can perform is to teach their students how to find information. At the rate science grows, most of what an information worker will need over his or her career will simply not have been known at the time the worker received a PhD. A library is not a zoo, with books in captivity and the curious looking in through the bars. Instead, a library has to be a way of finding information, and as the systems to do that become more complex, libraries have to expand their efforts of teaching people how to use these systems. And as so much of the information has not gone through traditional publishers, people need to know how to evaluate information, not just find it.
The value of finding information is growing steadily. It is now estimated that something like one third of the workers in developed countries are ``knowledge workers'' [Rubin 1986]. Peter Drucker has pointed out that the inputs into new industries are increasingly information, not parts and labor. The cost of an automobile, for example, is 40% materials and 25% labor, while the cost of a silicon chip is 1% materials, 10% labor, and 70% information. In medicine, a recent study has concluded that patients for whom MEDLINE searches are conducted promptly have significantly lower costs and shorter hospital stays [Klein 1994].
The question is whether libraries will cooperate, or whether they will fight each other and the online businesses for patrons. We already see a social problem in universities as the allegiance of the faculty shifts. Once, the typical professor of (let us say) surface physics of metallic thin films at any university would have thought of his colleagues as the other physicists at that university. Now, with the many conferences, phone calls, fax machines, and email, he is likely to think of his colleagues as the other surface physicists of metallic thin films around the world. Institutional loyalty is down, with some bad consequences for long terms programs (I know one student who was on her fourth advisor by the time she got her PhD, the others all having left her university). Could this happen to libraries?
Libraries will find themselves in a complex world. They will still wish to keep all kinds of things that don't seem to have much commercial value today. On the other hand, they may find many commercial databases competing with them to deliver the current, high-value information. And they may find that many different libraries are competing to deliver information to the same students. Inter-library loan, in an electronic world, may be a profit center rather than a nuisance. On the other side, libraries may find themselves with new opportunities. University libraries already offer to provide services to corporations; now this may be much more practical, and corporations which can not now afford libraries (or think they can't) will be willing to buy these outside services. For some low-usage information, libraries may be part of a bypass chain in which authors simply self-publish on the Net, and libraries provide the ability to find the material and the permanent copy. Since in the digital world location may be irrelevant, libraries will find that their users have far more choices than they have today. Libraries may find that there is a sorting out into ``supplier'' and ``consumer'' libraries, in which only a few large institutions supply information, and most of the rest simply access it on demand.
The likely future is that people spend more money getting information than they do today. Partly this will be because more information gathering is monetized, instead of being done by individuals. Partly this will be because more information will be available, and people will substitute looking things up for doing things (as architects and civil engineers are replacing physical models of buildings with simulations). But how do we avoid the fight for this money pitting one library against another, and causing wasteful competition? For example, consider a national library's choice of subscriptions to overseas journals today. If the national library wishes to maximize the number of photocopies people buy from it, it should subscribe to the most used and most common journals. These will be exactly the ones the university and public libraries subscribe to. If the national library wishes to provide a service to its country, it should subscribe to journals no one else gets, at the cost of its own usage statistics. We do not know how to resolve such issues today, much less in the more complex future world of digital libraries.
Economically, there are many dangers. Information distribution is a business with huge economies of scale, with bad consequences for stability [Lesk 1992]. Other industries with such economies of scale sometimes engage in destructive price wars in which everyone loses; consider the US airline industry as an example. The communications industry, by contrast, seems to have been able to preserve some financial health and permanence despite deregulation and competition. Libraries need to think about how we can charge for information, and how they can do this so that they remain viable organizations, able to carry on their function of preserving the world's memory.
We also need to minimize administrative costs. The current way that copyright permissions are handled in the United States makes it very difficult for libraries to simplify the use of digital information. IBM prepared a CD-ROM to mark the 500th anniversary of the first Columbus voyage to America. It is said that they spent over $1M on rights clearances, but only $10K went to rights holders, the rest disappearing in administrative and legal costs.
Perhaps the best model for information distribution is the distribution of software to corporations. Per-user site license pricing permits fair charging for both large and small users, with automatic checks on how many copies are in use at any one time. And individual corporations manage these contracts, so that the local user deals with only one purchasing and support operation, rather than having everyone buy individual copies of everything that is needed. Similar bargains by libraries could produce a world in which each library served as the ``information buying agency'' for its university or client group, making practical decisions as to whether copies should be mounted locally, bought on demand, or what. In practice, it would buy some things that today its clients get from bookstores; these would have a higher price, and be charged back to users in some way, but would produce greater total funding for the organization. The library would retain and augment its services in training and evaluation of information, although it would probably do fewer searches for people as they learned to do their own.
Such a model might support a world in which libraries could cooperate, rather than fight for patrons (called customers). Organizations of librarians need to encourage their members to work together, and to stop focussing on book purchases and turn their attention to training and education. This would also be a model for the next step in this process, in which the ready availability of university courses at remote locations causes universities to consider competing with each other for students. We will have to distinguish between ownership and access to courses, as well as books.
In summary, it is clear that digital libraries are coming, both in free and commercial versions, and in both image and ascii formats. This is an opportunity, not a threat. Digital information can be more effective for the users and cheaper for the librarians. Access will become more important than possession. But this must be used to encourage sharing, not competition. The real asset of a library is the people it has who know how to find information and how to evaluate it. It must emphasize its skills in training, not in acquisition. If we think of information as an ocean, the job of libraries is now to provide navigation. It is no longer to provide the water.
[Cummings 1992]. Cummings, Anthony. University Libraries & Scholarly Communication: Study Prepared for the Andrew W. Mellon Foundation, Association of Research Libraries, Washington, DC (1992).
[Egan 1991]. Egan, D.; Lesk, M.; Ketchum, R. D.; Remde, J.; Littman, M. and Landauer, T.; ``Hypertext for the electronic library? CORE sample results,'' Proc. Hypertext '91, ACM, San Antonio, Texas (Dec. 1991).
[Griffiths 1993]. Griffiths, J-M., and King, D., Special Libraries: Increasing the Information Edge, Special Libraries Association, Washington, DC (1993).
[Hill 1995]. Hill, Will; Stead, Larry; Rosenstein, Mark; and Furnas, George. ``Recommending and Evaluating Choices in a Virtual Community of Use,'' CHI 95, pp. 194-201, ACM, Denver, Colorado (1995).
[Hillstrom 1994]. Hillstrom, Kevin, ed. The Encyclopedia of American Industries, vol 2, Gale Research, 1994.
[Hoffman 1993]. Hoffman, M.; O'Gorman, L.; Story, G.; Arnold, J.; and Macdonald, N. ``The RightPages Service: an image-based electronic library,'' J. Amer. Soc. for Inf. Science, 44, pp. 446-452 (1993).
[Kenney 1992]. Kenney, Anne and Lynne Personius. Joint Study in Digital Preservation, Commission on Preservation and Access, Washington, DC (1992). ISBN 1-887334-17-3.
[Klein 1994]. Klein, M. S.; Ross, F. V.; Adams, D. L.; and Gilbert, C. M. ``Effect of online literature searching on length of stay and patient care costs,'' Acad. Med. 69, pp 489-95 (June 1994).
[Lesk 1991]. Lesk, Michael, ``The CORE electronic chemistry library,'' Proc. 14th ACM SIGIR Conference, pp 93-112, Chicago, Illinois (October 13-16, 1991).
[Lesk 1992]. Lesk, Michael, ``Pricing electronic information,'' Serials Review, 18, pp 38-40 (Spring-Summer 1992).
[McKnight 1993]. McKnight, Cliff. ``Electronic journals\-past, present ... and future?'' ASLIB Proc., vol 45, p 7-10 (1993).
[Niblack 1993]. Niblack, W.; Barber, R.; Equitz, W.; Flickner, M.; Glasman, E.; Petkovic, D.; Yanker, P.; Faloutsos, C.; and Taubin, G. ``The QBIC project: querying images by content using color, texture, and shape,'' Proceedings of the SPIE, vol 1908, pp. 173-87 (Feb. 1993)
[Odlyzko 1994]. Odlyzko, Andrew. ``Tragic Loss or Good Riddance: The impending demise of traditional scholarly journals,'' Notes of the AMS, 1994.
[Robinson 1993]. Robinson, Peter. The Digitization of Primary Text Sources, Office for Humanities Communication, Oxford University Computing Services (1993).
[Rodriguez 1995]. Rodriguez, Karen, ``Searching the Internet,'' Interactive Age, July 31, 1995, pages 28-30.
[Rubin 1986]. Rubin, Michael and Huber, Mary. The Knowledge Industry in the United States 1960-1980, Princeton Univ. Press, Princeton, NJ (1986).
[Taubes 1993]. Taubes, G. ``E-mail withdrawal prompts spasm,'' Science 262, pp. 173-174, (Oct. 8, 1993).